Cet article est une réinterprétation d'un article que j'avais rédigé en 2021, sur mon ancien site. J'ai essayé d'aller à l'essentiel et il présente, dans les grandes lignes, l'ensemble des pages Notion mises en place pour me permettre d'indexer ma consommation de café et tenter de construire une intuition sur la compréhension des mes goûts. De manière générale, je pense que se construire une base de connaissances est une bonne pratique quand on tente de découvrir une discipline. Étant loin d'être un expert en café et avec Notion, il est probable qu'une grande partie de ce que je décris dans cet article semble naïf ! Pour résumer, cet article présentera la manière dont j'ai mis en place une infrastructure pour indexer les cafés que je goûte, en vue de me fournir des métriques précises m'aidant à caractériser mes préférences, au moyen de l'outil Notion, tout en présentant quelques techniques et ruses apprises lors de la mise en place de ce système.
Indexation de café avec Notion
Alors que généralement, tant que l'on est pas tombé dans le monde très rigolo du café de spécialité, on se contente d'accepter une tasse, sans se soucier réellement des caractéristiques de ce que l'on boira. Pourtant, il existe beaucoup de critères qui influeront sur la tasse : la provenance des grains, la variété du café, sa méthode de sechage, le profil de torréfaction, la méthode d'extraction et bien d'autres. Un peu à la manière du vin, comprendre ce que l'on goûte est primordial pour appréhender le café de spécialité et pour développer l'intérêt que l'on porte au produit, comprendre comment choisir son café et comment le préparer correctement — en réduisant, potentiellement, le nombre d'étapes nécéssaires pour approcher, en fonction de ces caractéristiques, la tasse idéale.
Dans cet article, je vais présenter mon utilisation de Notion pour la construction d'un suivi de mes préparations (une base de données), me permettant de comprendre ma manière d'apprécier le café et d'être capable de définir, en fonction des méthodes d'extractions, une recette adaptée pour tenter d'extraire des tasses correspondant à mes préférences et, potentiellement, de m'adapter aux attentes de mes invités !
Par contre, cet article n'est ni un guide d'utilisation de Notion génériquement, ni une introduction au café de spécialité, c'est un compte rendu de modélisation sur la manière dont j'ai décidé d'organiser mon indexation de café pour collecter des métriques sur mes préférences.
À propos de Notion
Il est très difficile de résumer Notion autrement qu'en utilisant le néologisme idéateur. En général, quand j'essaie de le décrire à mon entourage, je le présente comme un outil de prise de notes, boosté aux stéroïdes, permettant de manipuler, entre autres, des spreadsheets comme valeurs de première ordre. Depuis plusieurs années, ce genre d'outils de prises de notes évolués est devenu très populaire et leur versatilité les fait s'inscrire dans une mouvance que l'on appelle NoCode/LowCode. On en trouve beaucoup et, à ma connaissance, les plus populaires (spécifiquement en extension d'outils de prise de notes) sont Obsidian, AnyType, Evernote et Notion. Je n'ai pas d'opinions très arrêtées sur quel outil privilégier — même si, pour des raisons idéologiques, je devrais passer un peu plus de temps à jouer avec AnyType, qui a le très bon goût d'être libre et local-first. De plus, une grande partie de ce que je vais présenter dans cet article pourrait parfaitement fonctionner avec un logiciel plus spécifique, comme Airtable par exemple ou encore avec une base de données relationnelle classique, mais quand j'ai commencé à indexer ma consommation de café, je voulais un outil générique pour assurer l'intégralité de ma prise de notes numériques.
En complément, à l'époque où j'ai rédigé la première version de cet article, Shubham Sharma parlait beaucoup de Notion sur sa chaine Youtube et il proposait une Formation gratuite pour prendre l'outil en main ! De plus, à cette époque, je travaillais chez Memo Bank et, l'un de mes collègues, Jonathan Lefèvre, avait, lui aussi, beaucoup de retours sur Notion et, à la relecture de la première version, m'avait fait l'honneur de me dire (approximativement dans ces termes) :
C'est toujours amusant et intéressant de voir un programmeur utiliser Notion, et, toi aussi, tu as trouvé un usage bien particulier et un peu flippant pour les non-initiés.
En bref, je ne sais pas si Notion est l'outil le plus adapté, et je ne sais pas si je m'en suis servi de manière pertinente (n'ayant pas eu pour objectif d'augmenter drastiquement ma productivité) mais après 2 ans d'utilisations, je suis assez satisfait de l'amélioration de la compréhension des mes goûts en matière de café !
Sur le NoCode/LowCode
J'adore réinventer la roue, il peut donc sembler étrange que je décide d'utiliser un logiciel propriétaire alors que je pourrais simplement réimplémenter toute une suite de logiciels dédiée au café ! D'autant plus que, sur un espace de conversation partagé que je fréquentais beaucoup en 2020, le NoCode (dont l'appellation LowCode était encore assez confidentielle) avait très mauvaise réputation.
Pour être honnête, je suis très favorable au NoCode/LowCode dans le sens où ils me permettent de me focaliser sur la problématique que je veux adresser et même si je suis convaincu que pour utiliser très efficacement des outils de ce genre, il vaut mieux être familier avec la programmation (qui requiert une certaine forme de logique et des qualités de modèlisation), mon seul réel reproche à cette collection d'outils porte sur leur nom. En effet, on programme toujours et l'utilisation d'un outil dit de "NoCode, ne dispense pas d'un architecte capable de construire une solution pertinente.
De mon point de vue, utiliser des Notion's et consorts me permet d'avoir de la génération de formulaires, gratuitement, et donc de pouvoir me focaliser sur le traitement de la donnée plutôt que sur la saisie, ce qui, dans beaucoup de cas, est un gain de temps monumental.
Par contre, comme évoqué précédemment, il est probable que 2024 soit l'année où je me pencherai sérieusement sur AnyType pour privilégier un logiciel libre et _local-first, parce que le fait de ne pas devoir écrire chaque ligne de code, caractère par caractère, me semble beaucoup moins problématique, idéologiquement parlant que de devoir me reposer sur des technologies propriétaires, pour lesquelles je n'ai pas de gouvernance de ma propre données.
Organisation de l'espace de travail
Notion permet de structurer des documents hiérarchisés — des documents peuvent en contenir d'autres. Chacun de ces documents sont une collection de blocs dont le comportement varie en fonction du besoin. On retrouve des blocs de titre, des paragraphe, des images, mais ils peuvent aussi référencer d'autres documents, des fragments de documents ou encore des vues paramétrées par des sources de données. La versatilité des blocs permet d'organiser proprement son espace de travail.
Comme un espace Notion ne sert pas qu'à un seul usage, j'ai organisé
l'ensemble de mes pages dédiées à l'indexation du café dans un
document, appellé sobrement Coffee (auquel j'ai ajouté l'émoji
:coffee: parce que je suis moderne et que j'utilise des
émojis). Ce premier document fait office d'ombrelle, on peut le voir
comme un espace nom ou encore un répertoire. Dans ce même
document, j'ajoute un nouveau document database (associé à l'icone
:disquette) dans lequel je placerai toutes mes tables. Ensuite, je
pourrai construire des vues (qui consomment ces tables), elles aussi,
dans le document Coffee pour adresser des services spécifiques. Le
fait de compartimenter la donnée brute est probablement une
coquetterie de développeur mais j'en suis satisfait.
Sur les bases de données
les bases de données Notion sont probablement une des fonctionnalités les plus utiles (de mon point de vue). Elles permettent de décire des tables, dans le sens qu'on leur donne dans le monde des bases de données relationnelles avec la possibilité d'embarquer des champs qui sont des formules dont la valeur est définie en dépendant d'autres champs. C'est en partie pour ça que je considère que les bases de données Notion sont à l'intersection entre une table et une feuille de calcul.
Comme il y a vraiment beaucoup de fonctionnalités attachées aux base de données, je tâcherai d'expliquer, au fil de l'article, les différentes fonctions utilisées (quand il y aura des ambiguïtés potentielles).
Premières caractéristiques
Maintenant que nous avons sommairement survolé quelques caractéristiques liées à Notion, nous pouvons nous intéresser au café, à proprement parlé. Notre exercice sera d'essayer de comprendre le cycle de vie du café, de l'arbre à la tasse pour extraire des éléments qui serviront à la modèlisation de notre système. Au travers de cette modèlisation, on pourra décrire une collection de tables qui serviront, ensuite, à décrire des vues pour répondre à des questions factuelles. C'est, de mon point de vue, la partie la plus amusante et j'ai l'intime conviction que, peu importe que l'on utilise du NoCode/LowCode ou que l'on programme entièrement l'application from-scratch, la démarche est identique (et fondamentale).
De l'arbre à la tasse
Pour dériver des modèles pertinents à notre indexation, il est important de comprendre le cycle de vie du café. En effet, en observant les différentes étapes par lesquelles on passe depuis l'arbre, jusqu'au café en grain qui servira à une préparation, on peut isoler une collection de critères qui influeront sur la tasse. N'étant pas (encore, je l'espère) un expert, il est probable que ma compréhension du cycle est naïve et maladroite, je suis donc ouvert à toute proposition d'amélioration !
Dans les grandes lignes, le commerce du café implique plusieurs parties :
- les producteurs, qui possèdent des fermes de caféiers et qui assurent le séchage des grains ;
- les exportateurs, qui rappatrient les grains vers des torréfacteurs ;
- les torréfacteurs, qui torréfient les grains ;
- les commercants, qui fournissent les revendeurs et les coffee-shops ;
- les préparateurs (baristas ou consommateur final).
Il est évident que ces différentes parties ne forment pas toujours des groupes absolument hétérogènes. Il est très courant qu'un torréfacteur soit aussi commercant (voire barista). Mais cette découpe des différentes parties impliquées nous permet de décrire un schéma sommaire du trajet du café, depuis l'arbre, jusqu'à la tasse :

-
La récolte :
Cette étape permet de mettre en lumière plusieurs critères. Premièrement, la région géographique où le café à été récolté, et par extension, le producteur (ou la ferme) et l'altitude du plan, le type d'arbre (naïvement, Robusta contre Arabica, même si, généralement, dans le café de spécialité, on ne trouve presque qu'exclusivement de l'arabica), la variété du café et des informations relatives aux dates de récoltes. -
Le séchage :
En tant que consommateur, on est habitué à me voir que du café en grain (voire moulu), mais le grain de café est le coeur d'une cerise. Il existe plusieurs techniques de séchages, naturel, lavé ou encore honey (qui possède plusieurs variations spécifiques) qui influent énormement sur le goût en tasse. Ce processus est une critère indispensable. J'ai l'intention d'écrire un article entièrement dédié à l'explication des différents processus de séchage.
En complément du séchage, certains producteurs ajoutent une étape de fermentation complémentaire (pouvant être, par exemple, anaérobique ou encore carbonique) qui, elle aussi, influe grandement sur les arômes du café. Au vue des conditions écologique, le café est devenu un produit de luxe dont l'importation peut se révéler coûteuse ce qui amène certains producteurs à expérimenter des techniques d'altérations aromatiques au moment de la fermentation influant, elles aussi, grandement sur les arômes du café. -
La torréfaction :
La torréfaction, grossièrement, la cuisson des grains verts, pour en révéler les arômes, joue en rôle essentiel (logique) sur la tasse finale. En France, c'est généralement le torréfacteur qui choisi les producteurs et les fermes avec lesquels il veut travailler ce qui nous permet d'extraire de nouveaux critères : le torréfacteur, le niveau de torréfaction, le profil aromatique du café et la date de torréfaction. -
La préparation :
La manière de préparer un café influe aussi très fort sur la tasse finale, et est conditionné par plusieurs critères : la recette utilisée, la quantité de café, la quantité d'eau, la taille de la mouture, la température de l'eau, la fraicheur du café, le temps d'extraction, en bref, toutes les variables de la recette. Ce qui nous permet de spéculer sur le fait que l'appréciation générale d'un café se fait par recette pour un batch de torréfaction précis.
C'est une vision assez large (et pour le moment, floue) des différents critères que l'on va utiliser pour décrire notre modélisation. Rassurez-vous, quand nous construirons explicitement les tables et les vues, je tâcherai de revenir sur les différents critères utilisés.
Les lecteurs plus attentifs remarqueront que je n'ai absolument pas parlé du processus d'exportation. Pour être très honnête, je n'ai aucune idée de comment ça se passe et je ne suis pas convaincu qu'il soit possible (de manière consistante), d'être aux faits de critères liés à l'exportation, c'est pour cette raison que je me permet discrètement de ne pas m'en soucier. En complément, la fraicheur des grains utilisés lors d'une préparation influent aussi sur la tasse, les conditions de stockages — type de récipient, exposition à la lumière etc. — devraient être un critère d'indexation. Cependant, comme j'utilise une méthode de conditionnement assez consistante (et que j'applique à tout mes cafés), je n'ai pas trouvé qu'il était pertinent de la mettre en lumière dans mon indexation !
Note sur la réplicabilité
Dans l'esquisse des critères que nous avons sélectionné, la recette joue un rôle très important. Pour que l'indexation soit pertinente, il faut donc être capable de reproduire précisement une recette et en collecter un maximum de métriques. De plus, imaginez que vous soyez en train de savourer la plus délicieuse tasse que vous ayez jamais produites, il serait terrible ne pas être capable de la reproduire pour des raisons d'imprécisions de mesure ! Pour cela, j'utilise une collection d'outils précis :
-
un moulin à cliques, le Commandante C40. Un moulin à clique permet de contrôler précisemment la granulométrie de la mouture et le Commandante est un moulin très polyvalent dont les réglages au cliques forment presque un standard de réglage. Le moulin est vraiment un outil nécéssaire car le café perd une grande partie de ses arômes 15 minutes après mouture ;
-
une balance, la Smart Scale 2 de Brewista, précise et doté d'un chronomètre, que j'utilise pour peser les quantité de café et d'eau. (Ce qui me permet d'éviter les mesures volumétriques, souvent assez peu précises et peu réplicables) ;
-
une bouilloire avec une gestion de la température précises (me permettant de changer degré par degré) et idéalement doté d'un col de cygne (pour le café filtre), j'utilise la Artisan Electric Gooseneck Kettle , elle aussi, de chez Brewista
Le dernier point peut sembler anecdotique, mais dans une tasse de café, ce n'est pas le café qui est le plus présent, mais l'eau. Ne disposant pas de purificateur d'eau, j'ai opté pour une carafe Brita, me permettant de diminuer au maximum le Potentiel Hydrogène de mon eau. A tout cela s'ajoute une collection de machines à café (un peu excessives) cependant, l'indexation peut ne commencer qu'avec une seule machine ! Et maintenant que ces clarifications sur la terminologies ont été évoquées, nous pouvons passer à la modélisation concrète de notre système dans Notion.
Modélisation des tables
Même si, normalement, on commence pas construire des user-stories
pour dériver un modèle pertinent, comme un espace Notion est moins
difficile à faire évoluer qu'une base de données utilisée en
production et que l'établissement un peu naïf du cycle de vie du café
nous donne des intuitions sur quels sont les variables que l'on
voudrait tracker, je me permet de construire des tables qui me
serviront à décrire la données que je voudrai exploiter dans des vues
spécifiques. Nous allons donc pouvoir remplir notre document
database avec des tables. L'ensemble de ces tables est organisée par
thème, mais je pense que pour les besoins de cet article, il n'est pas
nécéssaire de documenter cette organisation (qui est un peu à la
préférence de chacun).
Décrire les fermes/producteurs et les torréfacteurs
Même si je me suis intéressé tardivement aux fermes et aux producteurs, j'ai, à force de goûter de plus en plus de café, appris à détecter des fermes dont j'apprécie toujours les récoltes (par exemple, l'extraordinaire Finca Hartmann, de Panama). Donc avant de décrire une ferme sommairement, il est important de pouvoir la positionner géographiquement.
Un premier ensemble de tables: les zones géographiques
Attaquons-nous à notre première modélisation, où nous seront confronté à la construction de relation entre des tables ! Ma modèlisation est assez simple, je distingue 4 tables : Le continent, le pays, la région et la ville. Ces 4 niveaux me permettent d'avoir une granularité suffisamment fine (même si la terminologie n'est pas uniforme pour tous les pays. Par exemple, au Panama, on parlera de corregimiento plutôt que de région).
Je n'ai pas besoin d'informations autres que le nom (qui fait office
d'index) et d'un treillis de relation suivant cet ordre : cities -> regions -> countries -> continents. Voici une vue schématique du
modèle des zones géographiques (que j'ai placé dans un document nommé
Location) :

Vous remarquerez que j'ai ajouté des relations en pointillés (avec
le label rollup). Dans Notion, on trouve deux formes de relations :
- les relations standards qui référencent directement une autre table ;
- les rollups, qui décrivent champ de relation. C'est très similaire des Delegates en programmation orientée objets. En d'autres termes, un Rollup est un champ virtuel calculé depuis une relation.
Les Rollups permettent d'ajouter du contexte à ma table, et ne
doivent pas être remplis manuellement, en effet, dès que j'ai nommé,
par exemple, une région, et que je lui ai attribué un pays, le champ
continents sera automatiquement calculé. Il existe cependant une
petite restrictions aux Rollups, il est impossible de décrire un
Rollup qui prend un autre Rollup comme source. En effet, les Rollups
prennent toujours des relations en source. Dans le schéma de la
modélisation, on peut voir que je recense, par exemple, dans cities,
le pays et le continent dans lequel il se trouve, or, si l'on s'en
tient à mon affirmation sur les Rollups de Rollups, ça devrait être
impossible. Il existe une astuce !
La technique des champs miroirs
Dans notre exemple, on dispose des tables continents, countries,
regions et cities. Pour des raisons de lisibilité, je voudrais :
- les entrées de
countrieslistent leurcontinentassocié ; - les entrées de
regionslistent leurscountryet transitiviement leurcontinentassociés ; - les entrées de
citieslistent leurregion, transitivement leurcountryet transitiviement leurcontinent.
Nous savons que :
- les relations permettent de référencer un directement une entrée ;
- les rollups permettent de cibler un champ d'une référence (transitivement).
Comme un Rollup utilise toujours une relation comme source, il
n'est pas possible, dans le cas de cities de remonter le continent —
c'est d'ailleurs la seule table pour laquelle le problème se pose car
country ne peut n'utiliser qu'une seule relation pour exprimer son
continent, region utilise une relation pour exprimer son country
et un Rollup pour faire remonter le continent et dans le cas de
cities, une relation exprimera la region, un Rollup remontera le
country, mais on ne pourra pas faire remonter le continent.
Pour permettre à cities d'accéder au continent de regions, il
suffit d'utiliser un champ miroir, que j'ai appelé
_mirror_continent qui sera une formule et qui sera égal à
prop("Continent"). Ça a pour effet de créer un second champ qui est
strictement équivalent au champ Continent, sauf que ce champ n'est
pas le résultat d'un Rollup (et ce, même si c'est le cas de la
propriété Continent). Il devient donc possible de référencer ce
champs depuis cities en créant un autre Rollup pointant la région et
en référençant notre nouveau champ _mirror_continent qui lui, n'est
pas le résultat du calcul d'un Rollup, et rendre explicite le
continent dont fait partie une ville.
Pour les férus de l'encapsulation, Notion permet facilement de
cacher des champs de la vue générale, permettant de garder notre vue
de regions facile à lire. Dans la suite de l'article, je ne
distinguerai pas spécialement l'utilisation d'un champ miroir ou d'un
Rollup, le premier n'étant qu'un détail technique nécéssaire pour
combler une limite inhérente au Rollups.
Décrire une ferme
Maintenant que nous pouvons localiser une ferme, nous pouvons les décrire. L'exercice n'est pas très compliqué. En effet, je me contente de recenser les champs me permettant de construire un annuaire de fermes :

J'ai besoin d'un nom et d'un site (ou d'une page sociale) et
de référencer la ville dans laquelle se trouve la ferme. Et de
manière générale, je trouve ça intéressant d'avoir une rapidement
accès au pays, d'où la présence d'un Rollup (qui nécéssite d'ajouter
un champ miroir sur country dans cities). Maintenant, nous
pouvons décrire les torréfacteurs.
Décrire les torréfacteurs
La description des torréfacteurs n'est pas foncièrement différentes de celle des fermes. On y retrouvera des champs en communs — Nom, Ville, un Rollup depuis la ville vers le Pays et une Url. J'ai ajouté une adresse précise (essentiellement pour référencer une rue), car il est plus courant que je veuille me rendre dans la boutique d'un torréfacteur plutôt que dans la ferme du producteur et deux champs booléens pour exprimer si j'ai déjà testé de leur café et si le torréfacteur est encore actif.

Le fait de conserver les torréfacteurs inactifs me permet d'avoir une indexation cohérente. Le fait d'avoir un marqueur décrivant si un café dans du torréfacteur à déjà été goûté/testé permet de créer un premier outil. Cependant, quand notre modèle sera plus riche, il sera possible d'automatiser le calcul de cette cellule.
Un premier outil : torréfacteurs à essayer
Une des forces de Notion et qu'il est possible de construire des prismes de données, soit des vues qui appliquent des filtres et des méthodes de tris sur des bases de données existantes. On peut donc facilement construire une vue qui sert à lister l'ensemble des torréfacteurs encodés que je n'ai pas encore essayé.
Par exemple, en prenant cette table roasters (avec un tout petit
ensemble de données), on voudrait qu'une vue torréfacteurs à expérimenter n'affiche que L'Arbre à Café.

Pour cela, il suffit de construire une vue (avec le layout
Liste) auquel on ajoute un filtre
avancé
pour lequel on dit que l'on veut que le champ Tested ne soit pas
activé et le champ Active est activé. La construction de filtres
avancés est, de mon point de vue, assez intuitive :
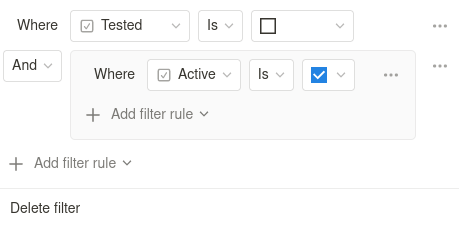
Ce qui, logiquement, produit une vue ne prenant que les torréfacteurs actifs et non-testés.

C'est en partie pour ce genre de possibilités que, à l'époque, j'avais décidé d'utiliser Notion. Il existe plusieurs gabarits de vues (par exemple, celle qui permet d'afficher les données sous forme de tables Kanban) et couplés et tris et aux filtres, il est possible de construire des vues spécifiques (et embarquables dans d'autres documents) pour répondre à des questions très précies. Dans la suite de l'article, nous illustrerons d'autres utilisations de ces vues.
Modèlisation du café, des variétés et des grains
On peut passer à la partie, de mon point de vue, la plus rigolote, on va décrire le café ! Même si l'existe plus de 130 espèces de caféiers, on en distingue généralement deux principales, utilisées pour faire du café : l'Arabica et le Canephora — que l'on appelle généralement Robusta. Dans le café de spécialité, on trouvera presque exclusivement de L'Arabica, qui est un arbre plus dur à entretenir mais qui produit du café de meilleur qualité. Ensuite il existe une très grande collection de variétés de café dérivés du Robusta et de l'Arabica, que l'on appelle des Cultivars (ou variétés cultivées). Dans les rubriques qui suivent, nous tâcherons de modéliser les tables décrivant les variétés de cafés pour ensuite décrire les grains torréfiés.
Décrire les variétés de café
Une première question de design se pose assez directement. Bien que
l'on sait que généralement, on aura une distinction entre Arabica et
Robusta, doit-on dédier une table pour décrire les caféiers ou peut-on
juste considérer que c'est un champ compacte — par exemple
is_arabica, étant un booléen et dont la valeur false impliquerait
que le caféier serait Robusta. Je n'ai pas d'opinion forte sur la
meilleure approche donc je vais dédier une table spécifique, ce qui me
permettra d'utiliser la page adossée à une entrée — dans Notion, il
est possible d'ajouter du contenu additionnel à chaque entrée dans une
table — pour collecter des notes relatives aux caféiers. On peut donc
décrire les variétés de cette manière :

Les espèces (species) ne sont pas très originales, je stocke juste
le nom bref et le nom complet. Ensuite, pour les cultivars,
je stocke un nom, un lien (qui pointe généralement vers
l'excellent index World Coffee
Research), une liste de noms
alternatifs (par exemple, la variété Villa Sarchi est aussi
appelée Villalobos), une espèce (Arabica ou Robusta) et des
potentiels cultivars parents.
La référence de cultivars parents permet de capturer des mutations génétiques artificielle ou naturelle. Par exemple, le Bourbon Rose est une mutation naturelle du Bourbon (un des cultivars les plus populaires) et le Mundo Novo est une mutation artificielle de Typica (probablement la variété la plus ancienne) et de Bourbon. Cette précision peut passer pour de la coquetterie, cependant, je trouve qu'avoir une idée approximative de la lignée de variétés permet d'avoir une meilleure compréhension des caractéristiques de ces dernières.
Maintenant, nous avons toutes les tables permettant de décrire les grains torréfiés.
Décrire les grains torréfiés
Nous avons tous les ingrédients nous permettant de décrire le grain que nous allons utilisé pour faire une tasse. Ce sera donc naturellement une des tables les plus touffue de notre système. Logiquement, nous retrouverons les producteurs (fermes) et les torréfacteurs, les régions (on pourrait imaginer que le producteur suffirait à décrire la région, mais je ne suis pas sur que toutes les fermes soient parfaitement situé dans une seule région, et certains grains peuvent être le fruit d'une collaboration entre deux fermes, où l'un fournit les cerises et l'autres pratique la fermentation, d'où ma nécéssité de dupliquer la région), on retrouvera la liste de variétés (quand un café n'est composé que d'une seule variété, on parle d'origine unique, quand il est composé de plusieurs variété, on parlera de blend) et d'autres champs que je décrirai aprés vous avoir présenté la structure (pour ne pas trop alourdir le schéma, j'ai pris la liberté de ne pas reproduire les tables des relations):

C'est le modèle qui, rétrospectivement, m'aura demandé le plus de
réflexion et il souffre de lacunes. Les champs Cultivars, Farms,
Roasters et Regions acceptent plusieurs relations pour
caractériser les collaborations et potentiellement les blends.
Le processus est décrit par le champ Process qui permet la sélection
dans une liste de méthode de séchage, cette liste peut évidemment
évoluer dans le temps même si, après plusieurs années de dégustation
de café, elle me semble exhaustive.
Ensuite on peut caractériser la fermentation, que l'on
énumérera. En l'état, j'ai observé l'absence de fermentation
complémentaire, (ou café aérobique), la fermentation
anaérobique, la fermentation carbonique et la fermentation
lactique (en cas de nouvelles découvertes, cette liste peut,
évidemment, changer). En complément du processus de fermentation
additionnelle, il est important de consigner la durée de fermentation
(en heure). Au contraire de Excel, il n'est pas possible d'invalider
cette valeur en cas d'absence de fermentation, cependant, il serait
possible (mais peut-être un peu exagéré) d'ajouter un champ de type
formule, qui utilise la valeur du champ Fermentation_duration si la
fermentation est différente de None et de renvoyer 0
sinon. L'infusion durant la fermentation est un booléen (pour
lequel il serait possible d'appliquer la même technique que pour la
durée de fermentation car cette infusion n'a de sens qu'en cas de café
fermenté additionnellement). On pourrait déplorer l'absence des fruits
ou arômes utilisés pour l'infusion mais, de mon expérience, la liste
des arômes (Flavours) fournies par le torréfacteur suffit pour me
faire une opinion.
Le niveau de torréfaction est une indication assez peu précise, en
effet, généralement, les valeurs dark et extradark ne sont jamais
utilisées dans le café de spécialité, les torréfacteurs cherchant
généralement à garder une trace du terroir. Et généralement, au plus
le niveau de torréfaction est élevé, au plus le café tend vers
l'amertume, qui est généralement une caractéristique que l'on veut
éviter (ou du moins contrôler). Après plusieurs années d'utilisations,
je n'utilise généralement que les valeurs light et middle. En
effet, comme il n'existe pas réellement de consensus sur les niveau de
notation du niveau de torréfaction, je suis assez approximatif.
Le champ Altitude peut être surprenant, en effet, nous aurions pu le placer au niveau de la ferme, cependant, j'imagine que certaines fermes peuvent étendre leurs plantations sur plusieurs hectares et donc, potentiellement sur plusieurs niveau d'altitudes. Je n'ai pas encore réussi à trouver une approche compacte et ergonomique de gérer des blends de plusieurs grains à plusieurs niveaux de récoltes.
Le dernier champ est le Score SCA, un score destiné à classer le café de spécialité, initié par la Specialty Coffee Association. Sa valeur est donc un indice très révélateur la qualité globale du café.
Même si le modèle n'est, malheureusement, pas parfait, il est, de mon point de vue, suffisant pour construire une sacré intuition sur mon appréciation générale du café.
Amélioration triviale
Quand j'ai partagé l'article sur différents réseaux, Quentin
Rault m'a, dans cette
conversation,
très cordialement fait remarquer que je pourrai diviser le modèle
beans en deux modèles :
GreenBeansdécrivant les grains avant torréfaction ;RoastedBeansdécrivant les grains après torréfaction (qui entretien une relation avecGreenBeans).
L'avantage de cette séparation, c'est qu'elle permet d'éviter la redondance d'informations quand des torréfacteurs torréfient les mêmes grains verts. En effet, les producteurs vendent le fruit de leurs productions à plusieurs torréfacteurs différents. C'est donc une amélioration triviale, améliorant largement le modèle.
Un second outil: diversifier les expériences
Comme dans beaucoup de disciplines qui proposent des paramètres variés — et ici, le nombre de champs décrivant des grains torréfiés et le nombre de processus de séchage promettent beaucoup de diversités — l'expérimentation d'un maximum de ces paramètres est capital ! C'est pour ça qu'en utilisant une vue, de type Kanban, utilisant le processus de séchage, par exemple, il est possible d'avoir assez rapidement une vision panoramique des grains qu'il faudrait plus tester. En 2021, après avoir construit la première itération de cette collection de tables pour indexer mon café, la vue Kanban des grains torréfiés m'a rapidement permis de me rendre compte que j'avais un peu trop délaissé les cafés Honey, me permettant de conditionner un peu mes achats pour diversifier ma connaissance du café !
Avec ce modèle, relativement modulaire, il est possible de jouer avec les vues, leurs approvisionnements dynamiques et les filtres pour faire remonter des signaux de consommation faible.
Maintenant, nous pouvons passer à la dernière étape de modélisation, qui tirera partit de toutes les étapes précédentes : les recettes !
Modèlisation des recettes et expériences
Même si nous avons modélisé quelques tables et que nous pouvons
relativement précisemment décrire des grains torréfiés, on peut
remarquer que à aucun moment, on a décrit l'interprétation (si on aime
ou non) d'une tasse. Même si nous aurions pu ajouter un champ
Personal_score (en contraste avec le score SCA) dans la table des
grains torréfiés, je pense que ça aurait été un champ un peu
flou. En effet, bien qu'il soit possible de retirer beaucoup
d'informations de notre modèle actuel, il reste beaucoup de
paramètres qui, selon moi, ne devraient pas être associés à la
description des grains. La fraicheur du café (sa date de torréfaction)
et la préparation mise en œuvre jouent un rôle capital dans
l'appréciation de la tasse.
Le fait de stocker des expérimentation de recettes m'a permis, au fil des dégustations, d'ajuster les recettes choisies en fonction des caractéristiques du café mais aussi d'ajuster paramètres par défauts d'une recette pour approcher, au premier coup la recette idéale. Pour permettre la saisie, de manière pertinente, des préparations, on va séparer la description de la recette et son expérimentation. Mais avant de décrire la recette, intéressons-nous à la description des machines à café.
Décrire les machines à café
Même si, de manière assez naïve, on pourrait croire que la description d'une machine à café ne consiste qu'a leur attribuer un nom — et donc qu'il n'est pas nécéssaire de leur dédier une table — on se rend vite compte que pour des soucis de commodités, on voudrait avoir une représentation hiérarchisée.
En effet, pour caractériser une machine, je peux soit utiliser un Multi-Select me permettant d'être assez libre concernant le niveau de granularité que je souhaite, soit je peux décrire un ensemble de tables hiérarchisées. Dans la version originale de l'article, j'utilisais un selecteur multiple, mais dans cette refonte, j'ai pris la décision d'utiliser deux tables. La première me permettant de décrire la catégorie de machine (par exemple Pour Over, French Press, Aeropress, Espresso etc.) et une seconde qui décrit plus précisemment la cafetière.

Rien de particulier à notifier, mais cette découpe permet de décrire une recette pour une catégorie de cafetières, et d'associer une expérimentation à une cafetière particulière. Maintenant, on peut décrire la description d'une recette.
Décrire une recette
On va pouvoir passer à la partie rigolote, on va décrire une recette ! Pour ça, on va utiliser une spécificité de Notion dont j'avais déjà un peu parlé dans la description des variétés de café. En effet, une entrée dans une table Notion attache automatiquement un document. Nous allons nous servir d'une table pour décrire les méta-données de la recette, et ensuite, nous utiliserons le corps de l'entrée pour décrire les différentes étapes de l'extraction. Auparavant, j'avais expérimenté des niveaux de modélisation plus fins, en considérant que les étapes étaient elles aussi des entrées dans une table, mais c'était très peu confortable et l'excès de normalisation rendait la description d'une recette compliquée.

Les premiers champs sont assez évident, on nomme la recette, et on lui attribue une source (généralement la page ou la vidéo qui la décrit) et on lui associe une catégorie de machines. Comme il arrive que certaines recettes soit spécifiquement designés pour une machine particulière, le champ Machine recommandée permet de tracer cette particularité.
La température de l'eau est un facteur qui influe beaucoup sur la recette, ainsi que la granulométrie de la mouture (que je compte en nombre de cliques dans mon moulin Commandante C40). Le dernier champ, le ratio permet de compacter le rapport eau/quantité de café.
Explication du ratio
Dans les descriptions de préparations du café que l'on peut trouver
dans la littérature, il est courant d'être confronté à un ratio. Le
ratio est une notation compacte permettant de décrire le rapport entre
la quantité d'eau et de café nécéssaire pour une préparation. Cette
notation permet d'éviter l'horreur de l'imprécision des mesures
volumétriques (par exemple, 2 cuillières à soupe de café) et ne repose
que sur le poids. En général, le ratio est décrit de cette manière :
1:X qui peut se lire de cette manière : 1g de café pour Xg d'eau.
Par exemple, un ratio typique des méthodes douces, 1:18, permet de
calculer très rapidement soit la quantité d'eau souhaitée pour une
portion de café donnée, soit la quantité de café souhaitée pour une
portion d'eau données (la magie de l'arithmétique) :
- pour 20g de café :
20 * 18=360gd'eau - pour 240g d'eau :
240 / 18=~13gde café
Dans mon modèle, je ne stocke que le X de la formule, le 1 étant
constant, ce qui me permettra de l'utiliser numeriquement dans un
outil.
Un troisième outil : un assistant de calcul
Maintenant que nous savons ce qu'est le ratio, nous pouvons créer un nouvel outil, qui nous permettra de définir la quantité d'eau à utiliser pour une recette spécifique, en fonction d'une quantité de café. On préférera souvent calculer la quantité d'eau en fonction du café plutôt que l'inverse car c'est plus souvent notre quantité de café qui conditionne notre recette plutôt que l'inverse et que généralement, on choisi son café avant de servir son eau.
Pour ce faire, nous allons créer, dans notre page tools une base de
données inline, qui ne contiendra qu'une seule entrée. Avec, en plus
du nom, 4 champs :
Recipe, une relation sur la recette que l'on voudra utiliser comme base ;Ratio, un rollup sur la relationRecipequi pointe vers le champRatio, nous permettant de rendre le ratio de la recette accessible ;Coffee, un champ numérique qui servira à contenir la quantité de café utilisée ;Water, un champformulequi affichera la quantité d'eau nécéssaire.
Maintenant que nos champs sont préparé, nous allons pouvoir construire
la formule. Même si l'opération arithmétique est très simple, le
modèle de relation de Notion implique quelques complications. En
effet, il n'est pas possible de forcer un champ à n'avoir qu'une
seule relation. Ce qui implique que la formule doit être écrite de
cette manière : prop("Coffee") * prop("Ratio").at(0). Qui peut se
lire de cette manière : multiplie la propriété "Coffee" par la
première valeur de "Ratio".
Cet outil nous montre quelques limites inhérentes à Notion, pouvant être ennuyante quand on essaie de faire des outils plus ambitieux :
- l'impossibilité de décrire une relation unique ;
- l'impossibilité de fixer la taille maximum d'une table. Ici, on voudrait limiter notre table à une seule entrée pour construire un véritable Widget.
- l'obligation d'avoir une clé primaire (
Name) qui, dans le cas d'une table à une seule entrée, ne fait pas réellement sens.
Même si ces soucis existent, et sont étroitement liés au modèle orienté tables de Notion, il est souvent possible de trouver une solution (parfois un peu verbeuse) de contourner le problème.
Décrire une expérimentation
A cette étape, on possède toutes les briques nécéssaires à réellement caractériser notre expérience gustative ! On va donc pouvoir décrire chaque expérience. Une expérience l'application d'une recette, avec une machine spécifique et du grain spécifique. C'est la partie qui va, enfin, nous faire remonter des métriques d'appréciation. En d'autres mots, une expérimentation est, à la fois, une variation, et une spécialisation d'une recette.
Comme une recette fait office de guide, certains paramètres sont dupliqués, pour permettre des ajustement en fonction du café utilisé, ou encore de la machine. Comme pour le déroulé d'une recette, nous pourrons utiliser le document généré par entrée pour collecter quelques notes complémentaires.

Une grande partie des champs a déjà été décrite dans les modélisation précédentes, on notera que par recette, je stocke la date de torréfaction, qui est un indicateur assez important concernant la fraîcheur du café torréfié. En effet, il est courrant de laisser le café dégazer quelques jours après torréfaction. Pour ma part, j'ai tendance à laisser le café se reposer jusqu'à une semaine post-torréfaction et de le consommer dans les trois semaines qui suivent cette semaine.
Le Score personnel est une note (sur 20), qui me permet de décrire un ressentit général sur la qualité de ma tasse. D'où l'importance de stocker l'heure à laquelle j'ai consommé mon café (ici, le champ Date) parce que certains café, de mon point de vue, ne convienne pas le matin (par exemple, les cafés fermentés). Ce champ sera capital dans les sections qui suivront car il nous permettra de faire remonter des métriques intéressantes.
Le champ Ratio nous permet de calculer le ratio (logique) en
fonction des quantité d'eau et de café et sa formule est assez
simple : prop("Water_quantity") / prop("Coffee_quantity").
Et le champ Fraîcheur du café est une simple soustraction,
affichant le résultat en semaines entre la date de préparation et
celle de torréfaction, et qui se matérialise par la formule suivante :
prop("Date").dateBetween(prop("Torrefaction_date"), "weeks"), ce qui
montre que le langage de formule de Notion est aussi très expressif
quand il s'agit de composer avec des dates.
Nous en avons fini avec la modélisation. A cette étape, l'exercice de saisir ce genre d'informations est déjà, selon moi, un grand plus dans la tentative de compréhension de ses goûts en café. Nous allons terminer sur une exploitation d'une fonctionnalité liée aux relations pour construire des outils de synthèses fins.
Plus de tableaux de bords
Maintenant que nous avons un socle de collecte de données complet, nous allons voir comment légèrement modifier nos modèles pour faire remonter des données amusantes et pertinentes. Par exemple, comment trier mes cafés favoris, faire remonter les fermes qui produisent les cafés que je préfère, quelles sont les machines qui produisent des résultats qui me plaisent le plus ? En l'état, l'ensemble de ces métriques est assez dur à collecter (dynamiquement), cependant, nous allons voir que grâce à une fonctionnalité très utile de Notion, il est possible de les implémenter. Pour l'article, nous nous focaliserons sur une seule des problématiques : comment, en se basant sur les scores des expérimentations, est-il possible de trier :
- les cafés que je préfère ;
- les torréfacteurs qui me procurent le plus de satisfaction ;
- les fermes/producteurs qui produisent le café qui me plait le plus.
En réalisant cet exemple, en chaîne, une collection de tableaux de bords, de plus en plus complexes deviendront triviaux à implanter. Cependant, pour que l'article ne quadruple pas de volume, nous nous contenterons de cet exemple.
Relations bi-directionnelles
Dans les propriétés d'une relation, il est possible de cocher la case
Show on relation_source qui, quand il est coché, ajoute un champs
dans la source de la relation, toutes les entités reliées à une
entrée. De ce fait, si dans la table experimentations, je coche
Show on pour Beans, alors par entrée de Beans, j'aurai toutes
les expérimentations basées sur ces grains. Couplé avec les Rollups,
il est possible de faire remonter, selon des agrégats, des valeurs.
Relations bi-directionnelles et Rollups : score moyen
Maintenant que toutes nos expérimentations sont accessibles par grains
depuis la table Beans, on peut ajouter un Rollup qui pointera la
champ experimentations, sélectionnant la propriété Personal_score
en utilisant comme fonction de calcul (le modificateur
calculate) Average. Ce qui aura pour effet de calculer la moyenne
des scores personnels des expérimentations par grains. Comme on
voudrait appliquer la même logique pour calculer le score moyen d'un
torréfacteur et d'une ferme, om va dupliquer ce champ calculé via la
technique des champs miroirs (la moyenne étant le résultat d'un
Rollup) et on va rendre bi-directionnelles les relations entre les
grains torréfiés et les torréfacteurs et les fermes. On peut donc
ajouter, respectivement dans les tables des torréfacteurs et des
fermes, un Rollup sur les relations fraîchement modifiés en
appliquant, ici aussi, la fonction de calcul Average.
On dispose maintenant d'un score moyen d'expérimentation par grain, d'un score moyen de grain par torréfacteurs et d'un score moyen de grain par producteurs. Ce qui nous permet de construire des vues dédiés pour afficher mes producteurs favoris, mes fermes favorites et mes grains favoris !
Pour ma part, après plusieurs années d'indexation, Finca Hartmann est la ferme à qui j'ai attribué le plus haut score et Cime est le torréfacteur qui arrive en tête.
En jouant sur la répercussion bi-directionnelle des relations, les
champs miroirs et les Rollups, il est possible de faire remonter des
métriques intéressantes et les possibilités sont incropyablement
variées, par exemple, il serait possible d'automatiser le calcul de la
case tested en utilisant un procédé similaire (et oui, si j'ai au
moins une expérimentations qui référence un torréfacteur, en d'autre
termes, que le champ expérimentation n'est pas vide, alors c'est qu'il
a été testé) ! Nous en avons fini avec ma procédure et mon système
d'indexation de café, il est temps de conclure.
En conclusion
L'article aura été, malheureusement, plus long que ce que j'avais espéré, et je pense que pour conclure correctement, il est nécéssaire de découper cette section en plusieurs parties. La première portera sur l'apport concret de l'outil d'indexation, la seconde portera sur Notion et, plus spécifiquement, sur le LowCode et la dernière portera sur l'avenir — hypothétique — que je réserve à ce système. En tout cas, j'espère que cet article vous aura, un peu, transmis mon intérêt pour le café ! C'est un monde fascinant, porté par des gens fascinants ! Une grande partie de mon intérêt pour le café a réellement commencé à se développer grâce à Clément, à l'époque du regreté Coøk Kaffé, me permettant de découvrir April, s'est amplifié grâce à l'expertise de Baptiste et à toute l'équipe de Cime, dont le café est excellent (et devenant mon torréfacteur favori) avec une mention pour Substance, où chaque réservation est la promesse d'un voyage incroyable et de découvertes, enrichi par de multitudes d'informations sur le terroir, les producteurs et la préparation, et Kultivar qui m'a offert l'opportunité de goûter des cafés fermentés de manière très originale et dépaysant ! Ce qui rend le monde du café de spécialité encore plus cool que le fait de pouvoir boire du bon café, c'est qu'il est tiré vers les hauts par des personnalités non-avares en conseils, en discussions et en partage !
Après ~2 ans d'utilisation
Avant de commencer à consigner consciencieusement mes expérimentations dans l'index présenté dans cet article, j'utilisais essentiellement le branding et la direction artistiques de torréfacteurs pour découvrir de nouveaux café. L'utilisation d'un index m'a permis, dans une phase de découverte, de diversifier volontairement mes choix, de comprendre — contextuellement — l'intérêt/l'appréciation que je pouvais avoir de certains café et me construire une intuition forte sur les arômes et la balance acidité/amertume que je recherche, généralement, dans des tasses mais aussi de trouver des premiers réglages pertinents pour expérimenter de nouveaux cafés. De plus, l'exercice de la documentation est vraiment un outil formidable pour stabiliser ses connaissances et même si je reste encore très néophyte dans le monde du café, je pense que j'ai pu plus apprendre et progresser grâce à cette indexation méticuleuse.
En bref, je pense que dans beaucoup de disciplines, la construction d'indexes, de bases de connaissances ou de dictionnaire est une bonne chose, et je pense que mon indexation de café aura été, pour moi, utile tout en me permettant de produire deux articles, ce qui, au vue de ma productivité rédactionnelle proche du néant, est une sacré aubaine !
Sur Notion et le LowCode
Même si, en tant que développeur, on regrettera certaines pirouettes obligatoires, j'ai trouvé Notion ergonomique et très amusant à utiliser. De mon point de vue, le modèle situé à l'intersection entre les tables relationnelles et les spreadsheets est très versatile et, couplé à l'utilisation de son API, il est possible de s'en servir comme d'un véritable back-end, offrant rapidement de l'UI pour des données structurées. C'était ma première expérience en LowCode/NoCode (autre qu'Excel) et je ne suis pas déçu. Même en utilisant un tout petit sous-ensemble de l'application (et passant à côté de pleins de fonctionnalités), j'ai été très impressionné par la vitesse de prototypage que ce genre d'outil permet.
Je vais continuer à lorgner sur les alternatives (idéalement libres et local-first) et continuer à expérimenter des technologies LowCode pour résoudre des problèmes que je n'ai pas spécialement envie de développer from-scracth. Si jamais vous avez des retours (positifs comme négatifs) sur Notion ou des suggestions d'outils LowCode/NoCode à expérimenter, n'hésitez pas à me contacter, je serais ravi de les découvrir.
En bref, bien qu'il ne soit pas possible, avec Notion, de construire tout ce qu'il est possible de construire avec une base de données relationnelles et un front-end dédié, l'outil couvre énormement de cas d'usage et offre un niveau de généricité très avancé, couplé à une sacrement bonne ergonomie et ça vaut probablement la peine de voir ce que le LowCode a à offrir. Dans mon cas, Notion m'a permis de bénéficier, sur base de la description de données et de structure de données, une interface graphique plus ou moins ergonomique, gratuitement.
La suite
La construction du système et sa documentation (cet article et son prédécesseur) furent des exercices amusants, aboutissant à un outil que j'utilise quotidiennement. En revanche, je pense que pour être génériquement ergonomique — donc être utilisable par une autre personne que moi, et donc potentiellement publiable sous forme de template ou du moins distribuable — il reste beaucoup de travail. En effet, j'ai estampillé, tout au long de cet article, des petits points de frustrations. Il est possible qu'ils ne soient présent que parce que je maitrise mal Notion (et si c'est le cas, n'hésitez surtout pas à me contacter pour m'expliquer comment améliorer mon système), mais je pense que comme tout outil tellement versatile, se voulant être facile à prendre en main, il est impossible de décrire avec précisions certaines contraintes relationnelles ou certains modes de formattages. C'est pour ça qu'il est possible (hypothétiquement) que je construise un logiciel dédié (et libre, évidemment) me permettant de relaxer toutes ces contraintes !
Quoi qu'il en soit, le prototype Notion sera d'une grande aide, car il m'aura permis de fournir une première modélisation, rendant l'usage du LowCode, comme un outil de prototypage, parfaitement pertinent !
Pour terminer, n’hésitez pas à boire du bon café, à laisser tomber les machines Nespresso, et à arrêter d’acheter du café trop fortement torréfié (à la Carte Noir ou Grand mère) en grande surface et laissez-vous tenter par les plaisirs du café de spécialité, cultivé, récolté, séché, et torréfié avec savoir, c’est largement meilleur. Promis.